Take a dictionary and observe how its content is linked together. How do you search for the meaning of a word? How can you find another word synonymous with that word? The dictionary is a paper example of a hypertext system. So are encyclopedias, product catalogues, user help books, technical documentation and many other kinds of books. Information is obtained by searching through some kind of index - the dictionary is arranged in alphabetical order, and each word is its own index. Readers are then pointed to the page of any other related information. They can read the information they are interested in without having to read the document sequentially from beginning to end.
Hypertext systems allow for non-sequential, or non-linear, reading. This is the underlying idea of a hypertext system. The result is a multidimensional document that can be read by following different paths through it. In this section we will look into the application of hypertext in computer systems, mainly the World Wide Web hypertext system.
The main use of hypertext is in information retrieval applications. The ease of linking different pieces (fragments) of information is the important aspect of hypertext information retrieval. The information can be of various media: it may be fragments of textual documents, structured data from databases, or list of terms and their definitions. Any of these, or a mixture thereof, can make up the contents of a hypertext document.
Therefore, in a hypertext system it is possible to:
link with a term that represents aspects of the content of a document
connect two related documents
relate a term to a fragment containing its definition and use
link two related terms
Such a hypertext system can store a large collection of textual and multimedia documents. Such a hypertext system gives the end-user access to a large repository of knowledge for reading, browsing and retrieving. This is a "database" of sorts, and is the reason why such a hypertext system is called a digital library. The Web started as an extensively large digital library. As it has grown in popularity, it has offered the possibility of interactive applications and commerce on the Internet, making it much more than a digital library.
To do:
Read about networked hypertext and hypermedia in your textbooks.
A hypertext document contains links referring to other parts of the document, or even to whole other documents. A hypertext document does not have to be read serially; the fragments of information can be accessed directly via the links contained in the document.
The links embedded in a document are known as hyperlinks. When selected, these hyperlinks allow for the portion of the document linked to by the hyperlink to be displayed. This allows the reader to jump to another part of the same page, another page in the same document, or another document. By following a series of hyperlinks, the reader can follow their own path through the document.
A computerised hypertext system implements this idea by including anchors and links in documents, which are usually represented by files. An anchor is a fragment of information which links to another document or portion thereof. It is the visual representation of a link. A link is the actual reference (or "pointer") to the other document. For example, in the diagram below, the fragment of Document A containing 'You can find this in Section 5 of B' is an anchor from which there is a link to the relevant section in Document B.
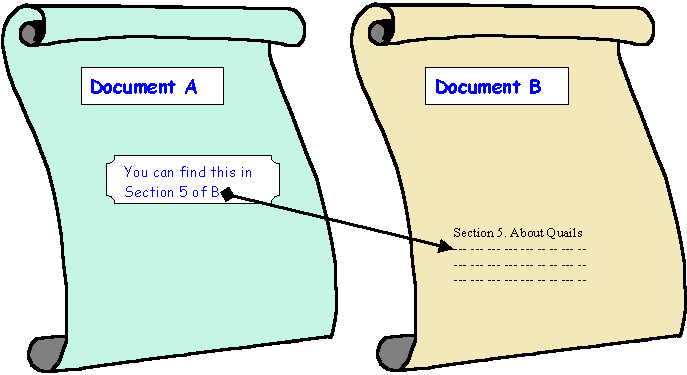
Take care not to confuse anchor or link. A link is a pointer to another piece of information within the same document or in another document; often you cannot see how that link is implemented (it may be a hidden URL or some other programmed mechanism). An anchor is a fragment of information which the user interacts with in order to access the link. For instance, in a Web Browser the phrase "Click here to return to the previous page" is the anchor which the user interacts with — it contains the link to the previous page.
A hyperlink must have unambiguous reference to the document: this is usually information on the document's location (where in some file space or network it is) and the mechanism to access it (called the communication protocol). In Unit 2 you will meet HTML anchors and how the referenced documents are identified and located with URLs.
A hypertext document allow links to portions of the document occurring before the link's anchor. This allows the reader to loop to portions of the document that they have already seen.
The table of contents in a book is a collection of anchors with explicit links to the internal parts of the book. Its bibliography is another collection of links but it refers to external information. To refer to the internal parts of the book is simple: the reader merely turns to the appropriate page, usually identified by page number. However, referring to the external information given in a bibliography requires a more complicated effort of searching.
In computer-based hypertext documents, the mechanism to follow a link (the jump) is automatic. Jumping to an external link (another document) is as easy as jumping to an internal link within the same document. As long as the link is sufficiently specified with the name and the exact location of the linked document, the user can directly access the linked document with a simple click on the anchor.
A series of successive jumps constructs a chained path through a series of documents. There is no limit as to the number of jumps, therefore the size of the chain is not constrained.
There may be more than one link in a page and the reader is free to choose any of these links to follow. The path a reader takes will then be different from the path of another reader. Each sequence of jumps forms a different path to fragments of the overall information in the hypertext document. Generally, there is no rigid order to read the information in.
There are two different but complementary purposes of chaining documents via links:
Focusing: At each jump along the path, the user can narrow the scope of the search until the fragment containing the topic of their interest is reached.
Broadening: Multiple outgoing links from a document allow the user to broaden their search. This is useful when the user does not have a precise idea of what is being searched for, or wishes to conduct a broad search in a certain domain.
Travelling through hypertext documents usually poses no technical difficulty. However, the reader might experience practical difficulties in retrieving a particular piece of information from a document with numerous alternative links.
Just as the reader is free to choose which links and jumps a path through a hypertext document is to follow, it is possible for a user to return to a point previously visited. In other words, loops may exist. A path may even return to the original (home) document. Hence, the structure does not necessarily follow a linear pattern; instead, the documents are connected together in a graph / mesh defined by the links.
This critical property shifts the burden of devising suitable exploration paths from the designer of a hypertext document to the user. This changes the way information is stored and retrieved. Instead of searching directly for information, hypertext allows browsing for information. However, the mesh of information creates difficulty in navigating through the hypertext document.
One of the original purposes for hypertext was the storage and management of textual documents. As computer and telecommunications technology has improved, the capabilities of hypertext systems have been extended to include any digitised media, such as sound and images.
This means that music and videos can be accessed via hyperlinks. This addition of multimedia to hypertext is known as Hypermedia. A combination of text, graphics, video or sound can now easily be interlinked in hypermedia document to offer a rich, often interactive, environment.
The process of preparing hypertext documents or, quite often, of converting a flat (linear) collection of documents into hypertext, is referred to as authoring.
Often an initial collection of documents has to be reorganised by splitting up the original documents into multiple sub-documents. Then links between these new documents must be constructed. Authors of hypertext documents are not only responsible for the content of these documents, but must link documents together, create paths through them, and build references that point to external documents associated to them.
Conceptually, related information is ultimately presented as a single, unique collection of hypertext documents. The remarkable aspect of hypertext or hypermedia documents that distinguishes them from other document types is that hypertext is 'shaped' by the user as he or she navigates the hypertext's network of link. Each sequence of links is a possible exploration path and each chosen sequence forms a single conceptual document for the user.
Table 1.1.
| Getting lost in 'hyperspace' | The easy linking of different fragments of information, crucial for browsing, can produce hypertext documents that are very difficult to use. The user may become disoriented when they do not know where they are in the document, and where he can go to. This problem of navigating a hypertext network is also known as being 'lost in hyperspace'. There are ways to minimise the risks of being lost in such a large information space. |
| Return path | The user simply backtracks through all the previous documents, link by link, until they reach the one they want to revisit. Alternatively, if the user remembers the reference of the required document, it may be selected from a list of the most recent documents explored. |
| Home page | The starting fragment in a path is known as the home page. This home page is usually a well-defined document that contains the first links to a certain path. It helps to remind the user the path he has taken before and may even serve as a starting point to another path. |
| Overview diagrams | This is the explicit display of the graph / mesh network of documents and links. Many websites have an overview site-map showing the paths the user may take to access certain information from the site. |
| Guided tours | These are suggested paths arranged by the document's authors. Its purpose is to assist the user in the exploration of information in hypertext document. Tour documents form a logical path sequence by using simple 'next-document' or 'last-document' anchors. |
| Direct jump | This allows the user to move directly to a portion of a hypertext document. The user has to know the name and location of the portion to directly jump to it. In a Web browser, the URL address of the website is typed in and the requested page is retrieved and displayed to the user. |
| Content-based retrieval | Some documents may offer a search facility. Browsing for information through the search facility can help narrow the information space to the domain of interest. However, most current search facilities are restricted to textual information only. |