
June 2010 Edition
Computer Science Department, University of Cape Town
| MSc-IT Study Material June 2010 Edition Computer Science Department, University of Cape Town |
An XML document is a serialised segment of text which follows the XML standard (which can be found at the W3C site).
XML's goals are set out in the W3C recommendations. Read these recommendations and, if some points are unclear, find out more about them.
An XML document may contain the following items:
a XML declaration
DTDs
text
elements
processing instructions
comments
entity references
The following image contains an example:
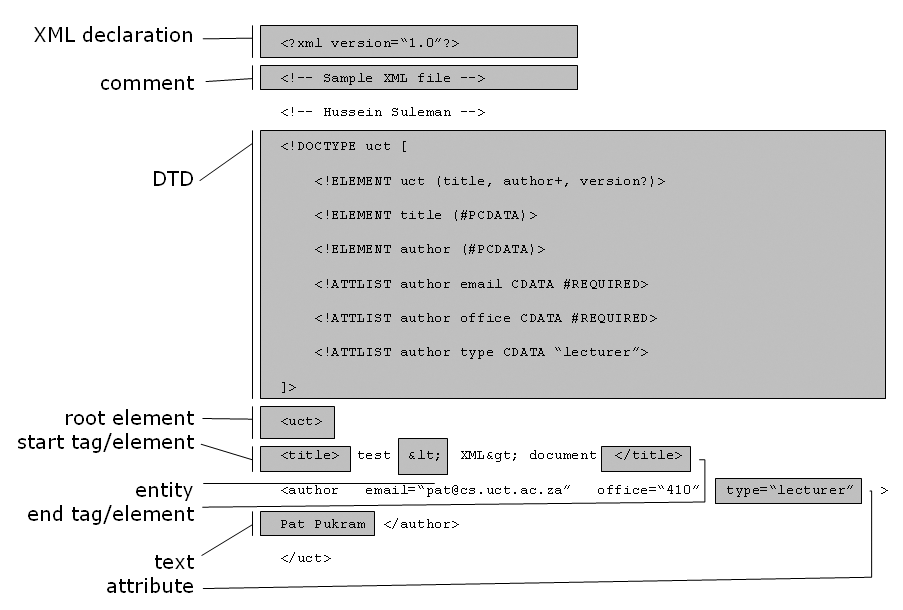
Well-formed XML documents have a single root element, and start and end tags are properly matched and nested. Valid XML documents strictly follow a DTD (or other formal type definition language). Well-formedness enforces the fundamental XML structure, while validity enforces domain-specific structure. SGML parsers, in contrast, have no concept of well-formedness, so domain-specific structure has to be incorporated into the parsing phase.
Why do you think it is important to validate XML documents? Discuss this with other students on the online forum.
The XML declaration appears as the first line of an XML document. Its use is optional. An example declaration appears as follows:
<?xml encoding="UTF-8" version="1.0" standalone="yes" ?>
encoding indicates how the individual bits correspond to a character set. See the next section for more detail.
version indicates the XML version.
standalone indicates whether an external type definitions must be consulted in order to correctly process the document.
The encoding used in the above example, UTF-8, is a Unicode-based encoding scheme. Most XML documents are encoded in the ISO 10646 Universal Character Set (also known as UCS or Unicode). Unicode at first supported 16-bit characters, as opposed to ASCII's 8-bits — this 16-bit format could encode 65536 different characters, taken from most of the known languages. This has since been expanded to 32 bits. The simplest encoding mapping this to 4 fixed bytes is called UCS-4. To represent these characters more efficiently, variable length encodings are typically used instead: UTF-8 and UTF-16.
The Basic Multilingual Plane (characters in the range 0-65535) can be encoded using 16-bit words. Endianness is indicated by a leading Byte Order Mark (BOM) e.g., FF FE = little endian. For more than 16 bits, characters can be encoded using pairs of words and the reserved D800-DFFF range.
D800DC00 = Unicode 0x00010000 D800DC01 = Unicode 0x00010001 D801DC01 = Unicode 0x00010401 DBFFDFFF = Unicode 0x0010FFFF
To match UTF-16 to UCS-4:
D801-D7C0 = 0041, DC01 & 03FF = 0001 (0041 << 10) + 0001 = 00010401
ASCII and endianness were mentioned in the last section.
UTF-8 is optimal for encoding ASCII text, since the first 128 characters needs only 8 bits to encode. Subsequent characters can be encoded using variable encoding. Here are some examples:
Unicode 7-bit = 0vvvvvvv Unicode 11-bit = 110vvvvv 10vvvvvv Unicode 16-bit = 1110vvvv 10vvvvvv 10vvvvvv Unicode 21-bit = 11110vvv 10vvvvvv 10vvvvvv 10vvvvvv etc.
Note that the first bits (until the first 0) are used to indicate how many bytes (set of 8 bit) are used to encode the character. Subsequent bytes for the same character encoding begin with 10. The data bits follow each of these header bits (represent by v's in the above examples) in each byte.
To match UTF4 to UTF-8:
0001AB45 = 11010 101100 100101 11110vvv 10vvvvvv 10vvvvvv 10vvvvvv = 11110000 10011010 10101100 10100101 = F09AACA5
Note that UTF-8, like UTF-16, is self-segregating to detect code boundaries and prevent errors.
The Document Type Definition (DTD) defines the structure of an XML document. Its use is optional, and it appears either at the top of the document or in an externally referenced location (a file). Here is an example of a DTD:
<!DOCTYPE uct [
<!ELEMENT uct (title, author+, version?)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT author (#PCDATA)>
<!ATTLIST author email CDATA #REQUIRED>
<!ATTLIST author office CDATA #REQUIRED>
<!ATTLIST author type CDATA "lecturer">
<!ELEMENT version (number)>
<!ELEMENT number (#PCDATA)>
]>
ELEMENT defines the basic units of the document's structure. In the above example, they are used to specify different elements (and sub-elements) of documents of type uct. The brackets () are used to specify either:
a list of child elements (sub-element). Each entry in the list can optionally be followed by a symbol each with a different meaning:
'+': Parent element must have one or more of this child element.
'*': Parent element must have zero or more of this child element.
'?': The existence of child element is optional.
In the example above the uct element must consist of a title element, at least one author element and it can optionally contain a version element.
The data type of the leaf-level element (i.e. elements with no children). In the above example, the title element is of type PCDATA (text). Alternatively the element could consist of an attribute list, which can be defined using the keyword ATTLIST in the following way:
<ATTLIST parent_element attribute_name attribute_type (#REQUIRED) ("default_value")#REQUIRED is optional and can be used to indicate that the attribute is required. default_value is also optional and can be used to specify default value for that attribute. In the above example, the author element consists of multiple attributes; namely email (required), office (required) and type (this defaults to "lecturer" if one was not specified).
Create a DTD for the following structure:
element: id_data
element: name
element: firstname
element: middlename (0 or more)
element: lastname
element: date of birth
required attribute: day
required attribute: month
required attribute: year
element: bloodgroup (optional)
You can find the solution at the end of the unit.
All elements are delimited by < and >. Element names are case-sensitive and cannot contain spaces (the full character set can be found in the specification). Attributes can be added as space-separated name/value pairs with values enclosed in quotes (either single or double quotes).
<sometag attrname="attrvalue">
Elements may contain other elements in addition to text.
Start tags begin with "<" and end with ">".
End tags begin with "<" and end with ">".
Empty tags (i.e. tags with no content, and the start tag is immediately followed by an end tag) can alternatively be represented by a single tag. These empty tags start with "<" and end with "/>". In other words, empty tags are shorthand. For example: <br><br> is the same as <br/>. This means that, when converting HTML to XHTML, all <br> tags must be in either of the allowed forms of the empty tags.
Every start tag must have an end tag and must be properly nested. For example, the following is not well-formed, since it is not properly nested.
<x><a>mmm<b>mmm</a>mmm</b></x>
The following is well-formed:
<x><a>mmm<b>mmm</b></a><b>mmm</b></x>
Most modern HTML browsers are able to successfully process improperly nested documents. Is this part of the HTML specification? Try to find out more about the similarities and differences between XML and HTML tags.
An element tag may indicate additional properties for its contents. For example, xml:space is used to indicate if whitespace is significant. In general, it is assumed that all whitespace outside of the tag structure is significant. Another special attributes is xml:lang which can be used to indicate the language of the content. For example:
<p xml:lang="en">I don't speak</p> Zulu <p xml:lang="es">No hablo</p> Zulu
Entities begin with '&' and end with ';'. Entities represent (refer to) previously defined textual content, usually defined in a DTD. For example, © can only be used if the ISOLat1 entity list is included. Character entities can be used to refer to Unicode characters. For example,  refers to decimal character number 23 and A refers to hex character number 41. Entities can also refer to predefined escape sequence entities such as < (<), > (>), ' ('), " (") and & (&).