
June 2010 Edition
Computer Science Department, University of Cape Town
| MSc-IT Study Material June 2010 Edition Computer Science Department, University of Cape Town |
XML parsers process both the data contained in an XML document, as well as the data's structure. In other words, they expose both to an application, as opposed to regular file input where an application only receives content. Applications manipulate XML documents using APIs exposed by parsers. The following diagram show the relationship.
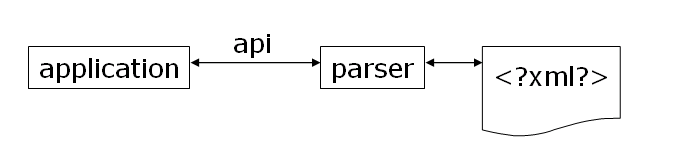
Two popular APIs are the Simple API for XML (SAX) and Document Object Model (DOM).
The Simple API for XML (SAX) is an event-based API that uses callback routines or event handlers to process different parts of an XML documents. To use SAX, one needs to register handlers for different events and then parse the document. Textual data, tag names and attributes are passed as parameters to the event handlers.
Read up about SAX on the Internet. A good page to start is the SAX project home page.
Using handlers to output the content of each node, the following output can be trivially generated:
start document
start tag : uct
start tag : title
content : test XML document
end tag : title
start tag : author
content : Pat Pukram
end tag : author
start tag : version
start tag : number
content : 1.0
end tag : number
end tag : version
end tag : uct
end document
The Document Object Model (DOM) defines a standard interface to access specific parts of the XML document, based on a tree-structured model of the data. Each node of the XML document is considered to be an object with methods that may be invoked to get/set its contents/structure, or to navigate through the tree. DOM v1 and v2 are W3C standards with DOM3 having become a standard as of April 2004.
Here is a DOM tree of our example:
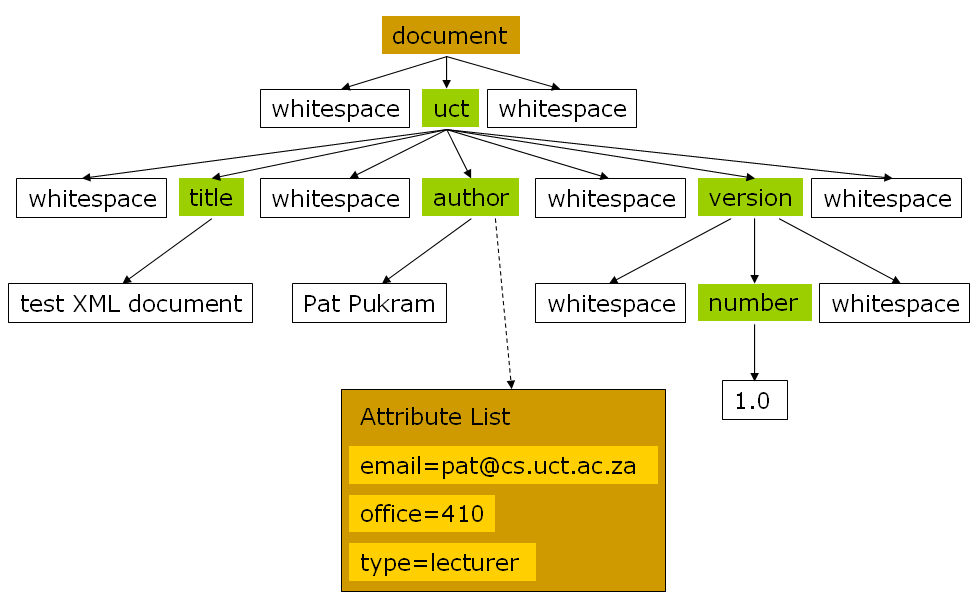
You might be able to understand the following code. Perl is a popular language to use in DOM processing because of its text-processing capabilities. Java is also popular because of its many libraries and Servlet support.
Step-by-step Parsing
# create instance of parser
my $parser = new DOMParser;
# parse document
my $document = $parser->parsefile ('uct.xml');
# get node of root tag
my $root = $document->getDocumentElement;
# get list of title elements
my $title = $document->getElementsByTagName ('title');
# get first item in list
my $firsttitle = $title->item(0);
# get first child — text content
my $text = $firsttitle->getFirstChild;
# print actual text
print $text->getData;
Quick-and-dirty Approach
my $parser = new DOMParser;
my $document = $parser->parsefile ('uct.xml');
print $document->getDocumentElement->getElementsByTagName ('title')->item(0)->getFirstChild->getData;
Different level of the DOM tree have different attributes and methods:
Document
attributes: documentElement
methods: createElement, createTextNode, ...
Node
attributes: nodeName, nodeValue, nodeType, parentNode, childNodes, firstChild, lastChild, previousSibling, nextSibling, attributes
methods: insertBefore, replaceChild, appendChild, hasChildNodes
Element
methods: getAttribute, setAttribute, getElementsByTagName
NodeList
attributes: length
methods: item
CharacterData
attributes: data
The DOM has different bindings in different languages. Each binding must cater for how the document is parsed — this is not part of DOM. In general, method names and parameters are consistent across bindings. Some bindings define extensions to the DOM, for example, to serialise (turn into a linear data structure) an XML tree.
Read up more about DOM on the Internet. You can start by looking at the W3C's section on DOM. Also make use of search engines.
Below we compare SAX and DOM.
DOM is a W3C standard while SAX is a community-based "standard".
DOM is defined in terms of a language-independent interface, while SAX is specified for each implementation language (with Java being the reference).
DOM requires reading the whole document to create an internal tree structure while SAX can process data as it is parsed. In general, DOM uses more memory to provide random access.