
June 2010 Edition
Computer Science Department, University of Cape Town
| MIT Notes Home | Edition Home |
| MSc-IT Study Material June 2010 Edition Computer Science Department, University of Cape Town | MIT Notes Home | Edition Home | |
In this section we look at some ideas and descriptions of how systems get designed. None of these processes of system development take much account of usability, but it is important to understand them so that you can understand the ways in which user centred design can be built into those processes.
The waterfall scheme for software development is the classic description of how software is (or should be) developed. There is debate as to how a good a model it actually is of the development process and plenty of variations on its theme have been suggested and described in many software engineering textbooks. Here we shall just concentrate on the classic waterfall model and its implications for user centred design.
Different schemes for development abound but the implications and challenges they set for user centred design are roughly the same.
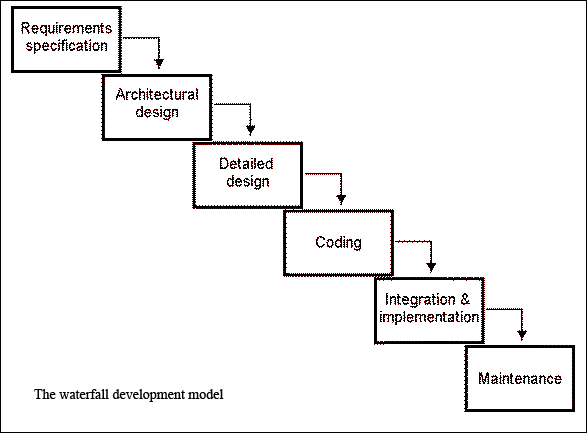
The waterfall model of software development (see Figure in next section) describes the stages that a development project should pass through from initial contact with the customer and requirements capture, through design and programming to implementation and maintenance.
For the rest of this unit we make the following distinctions: the ‘customer’ is the party who determines what is wanted of the software, and usually pays for it, the ‘users’ are those that actually have to interact with the implemented software and the developers are those that design and implement the software. It is important to realise that the customer need not be the user.
Also note that software is rarely developed on its own, it is usually part of a wider system that is being implemented. Dix et al use the example of aircraft development. The overall lifespan of an aircraft project can be up to fifty five years, from initial conception to decommissioning. Designing and building software subsystems for an aeroplane is just one part of the many processes that need to carried out to develop and run an aircraft successfully. In this unit we concentrate on the development of software systems, not on overall system development, which is a much wider concern.
In the following description we use the design of a car as an example; it is not a software system, but we use it because it is something familiar.
Now we step through each stage in the waterfall model, describing the activities that go on in each stage.
Requirements describe what a system should do. It is important to distinguish the description of what a system does, from the description of how it does it, which comes later in the cycle.
The developers should liaise with the customers to determine what problem the software is intended to solve or what work it is intended to support. They should also collect information on the environment in which the system is intended to sit, how it relates to any other systems and its user population.
The requirements typically form a contract between the customer and developers. The developers will be obliged to produced a system which does everything that the requirements say it will.
 |
Requirements therefore form an interface between customers and developers. The requirements must be understood by the customers, so they realise what they are paying for, and requirements must also be specific and precise enough that developers know what they are supposed to be building. Effectively, to produce a good set of requirements the customer and developers need to be speaking the same language. This may sound a trivial stipulation, but it can be surprisingly difficult to achieve. there are many documented problems where developers produce exactly what is described in the requirements only to find that the requirements do not describe the system that the customer actually wants.
If we were designing a car at this stage in the process we would try to address the problem we are trying to design the car to solve: are we racing the car? or is it a commuter car? or an off-road vehicle? Each of these would give us different requirements for the car: fast, efficient, comfortable, robust, etc. Note that each of these requirements states what is wanted of the car, not how it will be built.
Given a set of requirements the developers can now set themselves to the task of actually producing software. It is a well known software engineering maxim that the effort required to decompose a problem into lots of smaller problems, solve those small problems and then reassemble those solutions so that they solve the big problem is much less than the effort of solving the big problem in one go.
Based on this principle the architectural design phase decides how to break the problem presented by the requirements into smaller, tractable sub-problems. There may very well be software components available to fulfil some of the sub-problems identified as part of the architectural design phase. Decisions will be made as to whether it is more cost effective to purchase this software or develop it from scratch.
The result of the architectural design phase is the specification of several subsystems that can be developed independently of one another. There will also be a description of how to reassemble these subsystems into the system that satisfies the requirements.
In the case of the car design the car will be split into subsystems: engine, transmission, bodywork, steering etc, with specifications set for each of those subsystems. Those specifications should reflect the overall requirements set in the requirements specification stage. The transmission for an off-road vehicle will have very different specifications to the transmission for a fuel economic car. Also at this stage decisions will be made about buying the components ‘ready made’; will the designers design and build a new engine, or will they buy in an existing make of engine from subcontractors?
If the architectural design phase was conducted well then designers will be able to develop the specified subsystems independently of one another. Indeed in large projects the responsibility for subsystems may be contracted out to other software houses to develop.
For the car, detailed drawings of mechanical components will be produced and detailed assembly guidelines will be put together. At the end of the detailed design phase there should exist an accurate engineering model of the car, from which the car can be built.
Once the design for a subsystem is completed then programmers can start to produce code. The design phase is now firmly dealing with how a system performs. Once coded the subsystem will be tested to ensure that it fulfils its specification.
There are several techniques for ensuring that correct code is produced. Given that the specification of a subsystem can be expressed mathematically and that program code can be given a mathematical semantics it is possible to mathematically prove that given code is correct to the specification. Doing so is rather arduous, highly skilled and therefore expensive. Only developers of safety critical systems, where correct functioning is absolutely crucial, usually go to these lengths.
Typically a subsystem will be coded and then tested. Generally though it is never possible to fully test a subsystem.
For example, assume that a developer is working on a subsystem that turns off a fuel valve in a boiler when certain conditions occur. The specification will describe the circumstances in which the valve should be shut off: when a certain temperature or pressure is exceeded, or when too rich a fuel mix passes into the boiler. The software subsystem takes input from three sensors which give measurements of temperature, pressure and fuel mix. Let us say that each sensor produces a thousand different possible outputs (a very conservative estimate). Then the subsystem will have a thousand to the power of three (one thousand million) different input configurations. It is simply not possible to test this many configurations, and this example is much simpler than most subsystems developed in the real world.
Mathematically proving that a subsystem fulfils its specification is very arduous, but for all but the simplest subsystems it is impossible to fully test it. Typically subsystems will be tested against crucial inputs (in the case of our boiler it would be tested for the extreme values; the values that move the system from safety into danger, where the valve must work.)
Obviously a car is not coded, but the analogous phase in the design of a car is the production and testing of the individual components that have been designed.
Once the subsystems have been coded and tested then they can be assembled into the final system. At this point testing of the overall system will take place and usually the customer is brought back into the process to verify that the emerging system actually matches the needs that they expressed in the requirements. Once the customer verifies this then the system is released to the customer.
Given the manufactured and tested components from the ‘coding’ stage these can now be assembled into a working car. The overall car now exists and can be tested. Of course what is interesting is the extent to which it matches the original requirements set in the first phase.
Once a product is released, work can still continue on it in situ. Indeed it is very unlikely that the developers will have got the system completely right first time and so maintenance needs to take place. It must be noted that the development of a substantial system may take a year or so from requirement capture to implementation, but maintenance may last the working life of the system; twenty years or so. Therefore the major cost of the development actually lies in maintenance. Developing the system carefully may be initially expensive, but should reduce the effort needed in maintenance and therefore pay for itself.
Cars still need servicing and looking after while they are running. Generally this is up to the owner to attend to, but the manufacturer can also be held responsible with warranties and such like.
The waterfall model was developed in the seventies in order to give a framework and identifiable process to software engineering. At this time most software systems were inventory type batch processing systems, with little or no interaction with users.
Now that most systems are interactive, the appropriateness of the waterfall model has been called into question. The waterfall model is intended to develop systems that are primarily functionally correct. Requirements and specifications typically describe what the system should or should not do, and the waterfall model is intended to give developer a process whereby they can produce software that satisfies those requirements.
‘Non-functional requirements’ are not so much about what and how a system operates, but the way in which it operates. Non-functional requirements tended to be treated as of secondary importance to functional requirements. A typically non-functional requirement would be the reliability of a system. If a system did what was required of it, excellent, if it did that without breaking down very often then, that was a bonus.
In the waterfall model usability is considered a non-functional requirement and is therefore given a secondary importance, but in an interactive system usability should be considered as important as function correctness. (Which is not to downplay the importance of functional correctness – the most unusable systems are ones that do not work.)
Later we will briefly look at attempts to tag usability onto the waterfall model, by adding an ‘interface design’ phase. We argue that this is insufficient for genuine usability to ensured and that a concern for usability needs to be addressed at all stages in the waterfall process.
Another interesting consequence of the waterfall model is the cost of making mistakes. If you make a mistake somewhere in the process you usually need to cycle back in the process by going back to the phase in which the mistake was made, correcting it and then continuing through the phases from there. As a rule of thumb it is usually cheap to rectify a mistake if it is spotted soon after it was made. Hence if a mistake is made in the coding and it is spotted in the implementation phase then it is usually quite cheap to remedy. If, however a mistake is made in the requirements and it is not spotted until implementation then, in effect, you have to rebuild the whole system, which is very expensive. It is therefore absolutely crucial that the correct requirements are gathered, because the customer is only brought back into the process at implementation. If they identify a mistake then, or, more typically, realise that the system produced is not actually the system they really wanted, it is very expensive to remedy these problems.
The waterfall process is a structure to describe how developers should go about designing systems. The concept of design itself is interesting, and has its own particular terminology. In the next section we describe design and some of its terminology.
Design is about finding solutions to problems. Good design is about finding solutions that solve problems well. Given any problem there will be a myriad of different ways of solving it. These different ways are collectively called the ‘design space’. It is up to the designer to make a choice about which solution in the design space is best suited to the problem. A single decision is called a ‘design step’.
Also important in design is the notion of ‘discharging’ a design ‘obligation’. As a designer you are presented with a statement of a problem, which it is your job to solve. This statement of a problem is known as the obligation, (because you are obligated to solve it) and once you have solved a problem then you are said to have ‘discharged’ that obligation. So a design step is about devising a solution to a problem, and the step is held to be discharged successfully if the designer can demonstrate that their solution solves the problem.
Good design practice tends to put big decisions off as long as possible. If you think of the process of design as being the gradual narrowing of the design space until a single solution is arrived at, then a big decision at the beginning of the process will narrow the design space considerably and leave little scope for design decisions to be made later. ‘Never do today what you can put off until tomorrow’ is a popular and only half jokey maxim of good design.
Now if we think simplistically then for any problem there is a design space, and that design space can be partitioned into solutions which are usable, and solutions that are not. We obviously want to encourage designers to always choose a solution from the usable ones. The following approaches to user centred design are all about helping designers identify which solutions in the design space are usable and which are not.
Things are not that straight forward of course. Usability decisions are unlikely to be clear cut. So the following approaches sometimes also suggest what a designer should do in case of ambiguity and conflict.
The waterfall process is very rigorous and structured. In the next two sections we look at much less rigorous processes, in fact they are so unstructured it is difficult to describe them as processes at all. They are more rough approaches to development, or styles of development. While they are not structured or formal, they are quite common in the real world.
Why is it cheaper to make mistakes and rectify them early in the waterfall design process?
Answer to this question can be found at the end of the chapter.
What distinguishes a design step that is good from one that is correct?
Answer to this question can be found at the end of the chapter.
Whereas the waterfall model has a beginning, middle and end, evolutionary development has no such concepts. A system exists and is added to, modified and tinkered with over time to improve it.
The motivation for the improvements may come from different places: new advanced technology may become available that the maintainers of the system may want to use, or new ideas about how the system can be, or is being used, come to light and are incorporated into the system.
Typically innovations are implemented in two ways: firstly small improvements will be added to the working system without taking the system off line. Secondly, radical overhauls to the system may be decided on. In this case the old system will be left working in situ, while the improved system is built and tested concurrently. When the maintainers are happy that the new system is working well then the old system is phased out and replaced with the new.
A good example of evolutionary development is that of digital library systems.
Traditional paper libraries have been around for a very long time. Gradually automation is taking them over. Catalogues have been automated for a long time, and users have been able to electronically search to see if a certain book or journal is in the library, see whether it is on loan and find out which shelf it is housed on. Internet technology means that such catalogues can now be viewed by users at distance. A user can sit at their terminal and see if a book is in the library without having to go there to find out. Then the ability to order books remotely was added to the catalogue systems; the user need never leave their terminals, they could order books from the library and have them delivered to their desk.
Recently publishers have begun to produce journals and books in electronic as well as paper format, and distribute them on CD-ROM and DVD-ROMs. Users can search those media in the library and obtain electronic copies of the books or journal articles they want. Electronic documents can be delivered over the Internet, so the user can simply sit at their terminals and read documents straight away.
The waterfall model is not really sufficient for describing this process. Requirements change with the possibilities offered by the system. A developer designing an electronic catalogue system ten years ago could not really have foreseen the possibilities for libraries that have opened up with the Internet. It is safe to assume that the developers of current digital library systems cannot predict the way that information delivery will change over the next ten years either.
Lastly we look at revolutionary development. There is no set process to a revolution (by definition) and revolutionary software pops up now and again and changes the way we think about computerised systems.
The classic example are spreadsheet programs. The first was developed in the late seventies by a business student fed up of having to perform repetitious calculations. He developed an ‘electronic worksheet’ that did all the work for him. The concept seems obvious and simple now, but it revolutionised the way that many accountants work.
Revolutionary products come from a ‘eureka’ idea: a burst of creative thought that people are famously better than computers at producing. Eureka moments are not understood to any useful degree by psychologists and are therefore not really supportable or predictable.
It is salutary to note that though a lot of developers spend their time trying to formulate the next ‘big thing’, the number of genuinely revolutionary computer products in the past twenty years number about five, whereas as the failures that tried to revolutionise are legion.
Which of the cycles (applied science or task artefact) we described in the opening to this unit best captures evolutionary development?
Answer to this question can be found at the end of the chapter.
 |
Recall the analysis of web browsing you performed in unit 2. Now we shall proceed to use that analysis to redesign the web browser, hopefully in a more user centred way.
From unit 2 activity 6 should have resulted in a list of things that you actually did with your web browser, and activity 7 should have resulted in a list of things that your web browser lets you do. This activity compares the two.
Go through the list of browser functionality from unit 2 activity 7 marking off which of those functions you actually used in any of the tasks from activity 6. Apply the following scoring system: if you did not use a function score it 0, if you used it once or twice score it 1, if you used it several times (three to nine times) score it 2, if you used it a lot (over ten times) score it 3.
Now step back. How much functionality scored 0? Most of it? How many functions scored 3? I would guess that the Back' button scored a 3, and maybe the bookmark menu, if you use bookmarks. (Some users do not use bookmarks at all and so they would score a 0).
Now conduct a similar analysis, but this time score each function just with a single task from unit 2 activity 4. So score each function for searching, and then for browsing, and for any other task that you set your self. Now compare the scores for each different task. Do you use different functions for different tasks? I use my bookmarks a lot when searching and the Back button a lot when browsing, but not vice versa.
If you studied other users compile scores for each of them and see how they differ from your scores.
You may have completely different results to me, but one thing should stand out most of the functionality offered by the browser is not used. In other words web browsers are not very well suited to the tasks to which users put them.
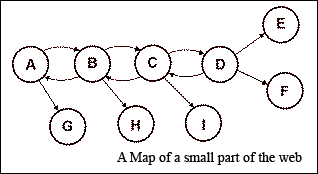
In particular lets look at the Back button: most users make great use of it, but can you explain what it actually does? Consider the map of a small corner of the web shown in figure 4. Each circle represents a web page and each arrow a link from one page to another. Imagine you start at page A and jump to B. On B you notice that there is a link to page H that looks interesting, but you first want to look at page C, so you jump there and then jump to page D. Now you decide that you want look at page H, so you need to backtrack to page B, this you do and then jump to page H. Now you press the Back button twice, where do you finish up? Page A or page C? Try and justify your answer.
So we have an even more damning argument for the usability of the browser; not only is most of its functionality unused, what the most used part of the functionality: the Back button actually does, is not very clear.
In summary we have shown that there is considerable scope for redesigning a web browser. This is what we shall look at in activity 4.
A discussion on this activity can be found at the end of the chapter.