
January 2011 Edition
Computer Science Department, University of Cape Town
| MIT Notes Home | Edition Home |
| MSc-IT Study Material January 2011 Edition Computer Science Department, University of Cape Town | MIT Notes Home | Edition Home | |
While the previous sections have mostly given advice and guidelines on designing the overall testing strategy, in this section we discuss more concrete advice on creating individual tests, with a focus on testing for implementation bugs (i.e., unit and integration testing) rather than validation and system testing.
An initial distinction to be made when creating a test is the difference between white-box and black-box testing. Black-box testing treats the module as an object whose inner-workings are unknowable, except for how the module handles its inputs and outputs. Black-box testing does not examine the module's inner state, and assumes that if the module correctly handles its inputs and outputs, then it is error free. White-box testing, on the other hand, also examines the module's inner state in an attempt to ensure that its internal operations are correctly performed, no matter how the module handles its inputs and outputs.
White-box testing allows us to conceivably test every line of code in the module: since we are examining the software's internal state, we can determine where and how that state changes, and so construct tests to exercise not only every line of code, but every logical choice that can be made when executing the code. This process of testing all lines of code and all logical choices in a software module is called exhaustive testing, and it is extremely important to realise that, except in the most trivial of cases, exhaustive testing is impractical to perform. To see this, one need only consider that whenever the software contains, for example, if statements within if statements, or loops within loops, the number of logical paths through the software increases exponentially, and so does the time required to test each of these choices. Even software of only a few hundred lines of code can quickly require more time than is feasible to test every logical decision that could possibly be made by the software. How this exponential explosion of choice is to be handled is an important aspect of white-box testing.
It will be useful to introduce some simple graphical notation for representing the execution flow of a program. While testing can (and often is) discussed without mention of flow graphs, they do provide a graphical tool for better describing the various testing processes.
Figure 9.1, “Flow graph notation”, displays various examples from the notation. The nodes in the graph represent some unit of processing that must occur. All logical decisions which affect the flow of program execution are represented by the edges in a graph: when an if statement decides on which branch to take (its then or else branches), this is represented by multiple edges leading to separate nodes. Similarly, various loops, case statements, and so on, are represented in a similar way.
An independent path through a program is a path through a flow graph which covers at least one edge that no other path covers. Examine Figure 9.2, “An example flow-graph”. The paths 1,2,3,5,7,8 and 1,2,3,5,7,5,7,5,7,8 are not independent, because neither of them have an edge which the other does not. However, the paths 1,2,3,5,7,8 and 1,2,4,6,8 are independent.
The set of all independent paths through a flow graph make up the basis set for the flow graph. If our testing can execute every path in the basis set, then we know that we have executed every statement in the program at least once, and that we have tested every condition as well.
While we may have tested every line of code, and every condition, we have still not tested every possible combination of logical choices that could be made by the conditional statements during software execution. In this way we limit the explosion of test cases the exhaustive testing would produce. However, this does mean that some bugs may still escape detection.
The cyclomatic complexity of a flow graph informs us how many paths there are in the graph's basis set (in other words, how many independent paths there are needing to be tested). There are three ways in which it can be computed:
By counting the number of regions in the flow graph.
If E is the number of edges in the flow graph, and N the number of nodes, then the cyclomatic complexity is: E - N + 2.
The cyclomatic complexity is also P + 1, where P is the number of nodes from which two or more edges exit. These are the nodes at which logical decisions controlling program flow are made.
In Figure 9.2, “An example flow-graph”, we can calculate the complexity in all three ways. There are four regions in the graph (remember to count the space surrounding the graph, and not only the spaces inside the graph). There are ten edges and eight nodes. There are three nodes from which two or more edges leave. Using the three methods above, we get:
Four regions give a cyclomatic complexity of 4.
Ten edges and eight nodes give a cyclomatic complexity of 10 - 8 + 2 = 4
Three nodes with two or more exiting edges gives a cyclomatic complexity of 3 + 1 = 4
Figure 9.1. Flow graph notation
 |
A sequence flow graph
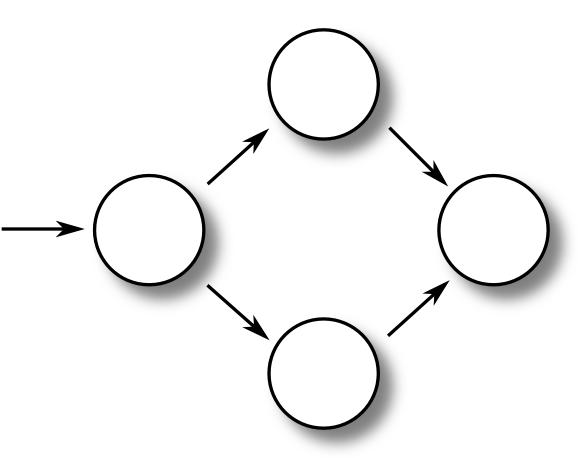 |
An if statement flow graph
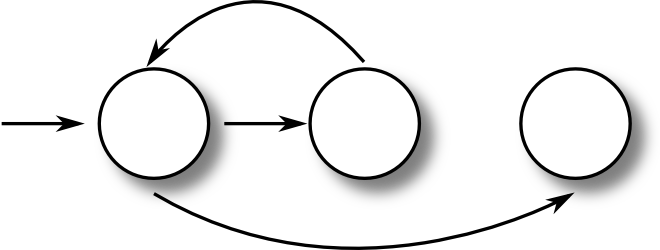 |
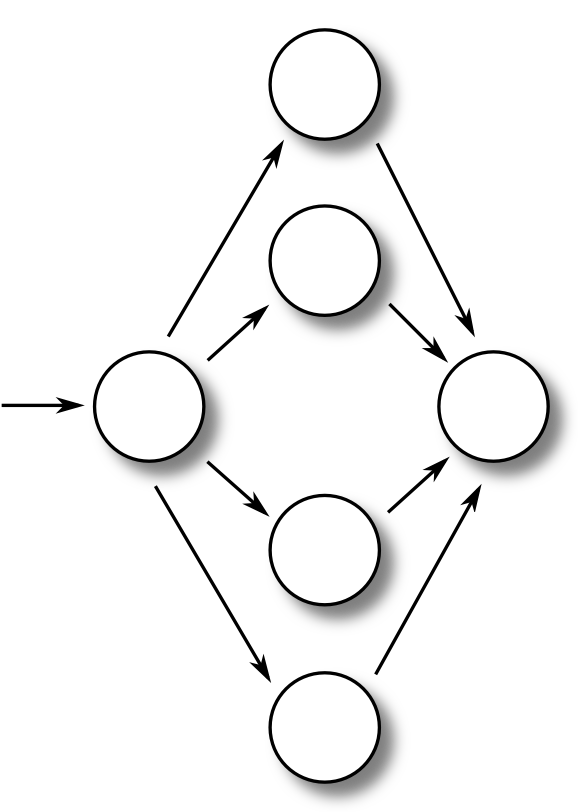 |
A case statement flow graph
 |
An until statement flow graph
Figure 9.2. An example flow-graph
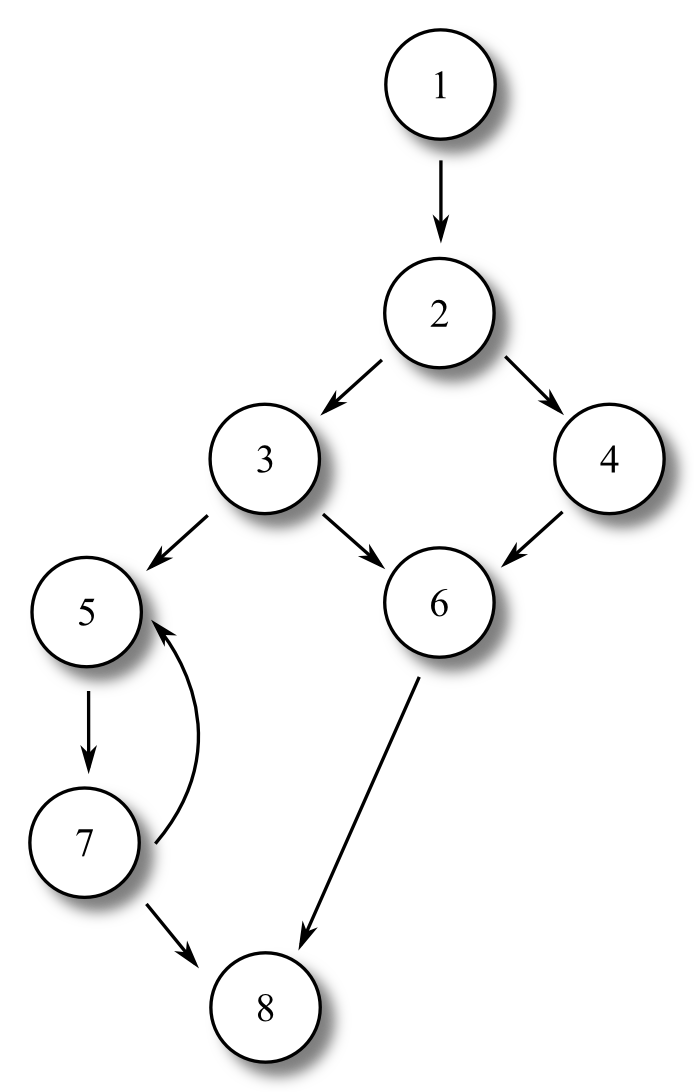 |
An example flow graph, with labeled nodes. Execution begins at node 1, and proceeds through an if statement, and possibly through a loop. Execution terminates at node 8.
As we can see, each method agrees with each other, and states that there are four independent paths through the program.
The third definition has broad applicability, since it provides a method for calculating complexity without using flow graphs: one can merely count the number of conditional statements in a program and add one to this number.
These concepts of independent paths, basis sets and cyclomatic complexity are important to testing, because they give us a concept of how well our tests may be exercising the code. Importantly, those portions of the code which are used least are the portions which are the least likely to be tested, and the most likely to retain their errors. Discovering the independent paths through a program, and testing them all, allows us to ensure that these errors do not go unchecked. Various studies have also shown that the higher the cyclomatic complexity of a given package, the more likely it is to have errors.
We want to again point out that testing all independent paths is not the same as exhaustive testing. Exhaustive testing wishes to test all possible paths through the flow graph, as determined by examining all possible combinations of logical choices that could occur at the conditions. In the particular example used here, the number of all paths through the program depends on the number of times that the loop needs to iterate. If the loop were to contain other loops, or if statements, this number of paths would increase dramatically. The use of independent paths keeps the number of tests to a reasonable level, while ensuring that all lines of code are tested.
The testing methodology which tests all independent paths through an application is called basis path testing, and is clearly a white-box testing method.
Basis path testing can be tedious to perform. It does provide suggestions for determining tests in general, however. When determining how to test code, always test the logical conditions (this is called condition testing). Also, focus on the conditions and validity of loop constructs (loop testing).
While white-box testing is interested in how the module performs its function, black-box testing is interested only in what the module should be doing. Black-box testing tests the requirements of the software module, and not at all with how it manages to meet these requirements.
These requirements cover a wide range of areas to be tested, and includes:
Input and output errors, which includes not only errors which may occur when making use of the software module, but also errors that may occur when the software module attempts to use other modules, such as a database.
Incorrect and missing functions.
Initialisation and termination errors.
Behaviour errors.
Performance errors.
Reliability errors.
We will examine two methods of black-box testing: equivalence partitioning and boundary value analysis.
Equivalence partitioning divides a software module's input data into equivalence classes (note that these are not classes in the sense of object-oriented programming). The test cases are then designed so as to test each one of these input classes; a good test case will potentially discover errors in whole classes of input data.
Generally, for any input, we will have at least two classes. For example, if the input to the software is a Boolean, then this is clearly the case (in this case, each class has one value: one true, the other false). Similarly, if the input is a member of a set, then you will have multiple classes. For example, if we had a software module from a graphics package which, when given a rectangle, used the lengths of its sides to determine whether the rectangle was a square or not, then we would have two classes: one for the rectangles which are square, one for rectangles which are not.
The number of classes strongly depends on the type of the input data. If the input data requires a specific number, then there are three classes: one for that number, one for all numbers less than it, and one for all numbers greater than it. Similarly, if the input should be from a range of numbers, we again have three classes.
Testing each input class reveals whether the software module correctly handles the range of input that it could receive.
Software bugs tend to occur more frequently at their “boundary values”, which are those values around which a conditional changes the value it evaluates to. For instance, boundary values are those values for which an if statement will change between choosing to execute its then or else portions, or where a loop decides whether to iterate or not.
This increase in errors can occur for simple reasons, such as using a greater-than comparison instead of a greater-than-or-equal-to comparison. When looping, common boundary mistakes include iterating one time too many, or one time too few.
Because of the increased frequency with which errors occur around boundary values, it is important to design test cases that properly exercise the boundaries of each conditional statement. These boundaries will occur between the various input classes in the equivalence partitioning method, and so boundary value analysis is well suited to being combined with that method.
Testing methodologies can be modified slightly when the software is developed in an object-oriented manner.
The basic “unit” for unit testing becomes the class as a whole. This does have the consequence, however, that the various methods cannot be tested in isolation, but must be tested together. At the very least the class's constructor and destructor will always be tested with any given method.
Similarly, when performing integration testing, the class becomes the basic module which makes up the software. Use-based is a bottom-up integration method constructing the software from those classes which use no other, then integrating these with the classes which use them in turn, and so on. Classes can also be integrated by following program execution, integrating those classes that are required in order to respond to particular input (thread-based testing), or, similarly, to integrate those classes which provide some specific functionality, independent of the input to the software (cluster testing).
In general, you should not only test base-classes, but all derived classes as well. Inheritance is a special case of module integration, and should be treated as such.